 .
.
In case you're interested in the source code, I put in on github. The PDF can be downloaded from here (http://renenyffenegger.ch/blog/files/a4-ruler.pdf).
.
In case you're interested in the source code, I put in on github. The PDF can be downloaded from here (http://renenyffenegger.ch/blog/files/a4-ruler.pdf).
\b, at least not in Oracle 11i.
Consider the following table:
Now, I want to find all records that contain the exact word Foo.
That is, I want, for example A Foo without a Baz (the fourth record), but I don't want
A FooA BarAndABaz (the second record) because FooA is not the exact word Foo
If Oracle supported \b I could use
To improve matters, I could try
A bit better, but far from perfect. For example, the fifth record (Foo Bar, Baz) is not returned, because
the \s doesn't match start of line. So, I improve the where condition:
Yet again, this is far from perfect. I need also record records where Foo is followed or lead by a non word character (such as ? or -):
clip.exe, that can be used to quickly copy something into the clipboard from cmd.exe.
For example, if I wanted to copy the current working directory into the clipboard, I'd go
Similarly, if I needed to copy all files within the current directory, I'd do
Also, I can copy the content of a file into the clipboard like so:
Here's a table to demonstrate it:
Now, a select statement with fetch first row only:
c:\temp\colors.ps1):
When executed with something like
It prints
Here's a simple module to demonstrate that
And here's a script that uses SomeModule:
This script can call exp_one and exp_two from SomeModule because these two functions are listed in @EXPORT. Functions listed in @EXPORT are by default exported into the user's namespace.
ok_one, on the other hand, cannot be called directly as it is not listed in @EXPORT. It can, however, be called so SomeModule::ok_one().
Here's another script:
Now, I specify the identifiers I want to have imported into my namespace (qw(ok_one ok_two)). Accordingly, I can call these.
I cannot call exp_one (which I could call in the first script), because as soon as I begin specifying identifiers to be exported I need to specify all of them.
Of course, it will soon be tiresome to always indicate which functions I want to have imported. Therefore, I can define tags with the %EXPORT_TAGS hash that groups multiple identifiers under a tag. For example, the tag all imports all functions. In my case, I just used the combined values of @EXPORT and @EXPORT_OK. This is demonstrated with the third script:
Lastly, I can import some functions, too:
Ususally, the cause for this error is that someone is granted access to a table via a role rather than directly. So, the user can select from that_table but as soon as he uses the statement in a compiled PL/SQL source, it won't work anymore, erroring out with this ORA-00942.
I can demonstrate this easily: First, a fresh user is created and given a few privileges:
select_catalog_role so he can do
This procedure won't compile for the reasons outlined in the beginning of this post:
So, what to do? For such reasons, I have created the IPC PL/SQL package. The package's function exec_plsql_in_other_session uses dbms_job to create another session that can make full use of the granted privileges and also uses dbms_pipe to return a value to the caller.
Of course, I need to grant the required privileges also:
After installing the packages, I can rewrite my function like so:
Now, I can use the function to report some memory figures
Under some special circumstances, it prints
Of course, this is impossible if PL/SQL were executing correctly. Either guid_ is null or it has a value. Since the if statement executes the dbms_output line, I should assume that guid_ is indeed null. Yet, a value for guid_ is printed.
This behaviour can be reproduced, at least on Oracle 11R2, with the following code:
I have also asked a question on stackoverflow.
K-NN can be used to classify sets of data when the algorithm is fed with some examples of classifications.
In order to demonstrate that, I have written a perl script. The script creates two csv files (known.csv and
unknown) and a third file: correct.txt. The k-NN algorithm will use known.csv to
train its understanding of a classification. Then, it tries to guess a classification for each record in unknown.csv.
For comparing purposes, correct.txt contains the classification for each record in unknown.csv.
known.csvknown.csv is a csv file in which each record consists of 11 numbers. The first number is the classifaction for the record. It is a integer between 1 and 4 inclusively. The remaining 10 numbers are floats between 0 and 1.
unknown.csvunknown.csv, each record consists of 10 floats between 0 and 1. They correspond to the remaining 10 numbers in
known.csv. The classification for the records in unkown.csv is missing in the file - it is the task of
the k-NN algorithm to determine this classification. However, for each record in unknown.csv, the correct classification
is found in correct.txt

To make things a bit more complicated, two random values in the range [0,1] are added to the eight values resulting in 10 values. These two values can either be at the beginning, at the end or one at the beginning and the other at the end.
Number object has the toFixed method that allows display a number with a fixed amount of digits after the decimal point. Unfortunately, it doesn't round the number.
sys.ora_mining_number can be used to turn a set of numbers to a result set:
I still find this quite funny, so I had to post it on this blog!
Shape object of MS-Word can be used to insert pictures into word documents with VBA. If I insert a small picture and blow it up to use the entire page size, it creates a cool, almost psychedelic effect.
Here's the image:  Its size is 20x30 pixels, approximately the aspect ratio of an A4 document.
Its size is 20x30 pixels, approximately the aspect ratio of an A4 document.
The function, named main needs a parameter, path, that points to the location of the image:
First, we declare a variable for the image (background_image), which is a shape), then load an image and assign it to the variable:
Then, we need to place the image's top left corner on the page's top left corner:
Finally, we want the image to be behind the text in case we're going to write on it:
This VBA program should be saved into a file, for example backgroundImage.bas. It can then be executed with a
The resulting word (or image) then looks like

runVBAFilesInOffice.vbs.
First, I create a small schema with some simple grants:
The first user (a_user) is needed to contain a few tables to test if grants to these tables will be cloned:
The second user (user_to_be_cloned) is the user that I will actually duplicate:
I also need a role through which I will grant an object privilege:
Creating the mentioned tables:
Granting some privileges:
Now, I want an sql script that contains the necessary statements to clone the user. The following script uses the SQL*Plus spool command to create the file (so it is designed to be run in SQL*Plus).
It also uses replace a lot to change USER_TO_BE_CLONED to CLONED_USER.
The created script can now be used to create the cloned user. After logging on with CLONED_USER you can verify that the grants are cloned, too, by trying to select from a_user.table_01, a_user.table_02 and a_user.table_03.
Here's what it boils down to: UBS has lots of data and everybody talks about turning Big Data into Big Money. This is exactly what UBS want to to. The problem: UBS lacks the expertise and know how to tackle this kind of problem. After all, they're a bank. So, what can they do?
They could go to one of the many new Big Data consultancies that spring up like mushrooms these days and ask them for a solution. Yet, that is risky. How can a bank determine if such a consultancy is worth the money, especially in a field where those companies are relatively young. UBS could contact many consultancies. Of course, that will drive prices even higher. There must be a better way.
Indeed, UBS has found a better way. They do the UBS Innovation Challenge. Everybody can participate with ideas tailored to the UBS problem domain. UBS screens those ideas, selects a "best idea" and gives the winner SGD 40'000. There are additional costs, such as flights to Singapore and accomodations for the final participiants, but the costs for UBS are manageable.
So, UBS benefits in two ways: 1) They are presented with not only one or two ideas but with many ideas. 2) The costs for these ideas is known in advance.
First, I create a table that contains the count of nodes per pixel. I fill this this table with a create table... as ...count(*).... group by. The values for the variables a through f determine the aspect ration and the size of the resulting picture:
x and y are unique. This pair represents a pixel on the final image. cnt is the number of nodes that fall into the area covered by a x/y pair.
After filling this table, I can iterate over each pixel and draw a color that is lighter for large pixel counts and darker for small pixel counts. I use the Python Image Library (import Image) to draw the image.
Here's the result:

The same picture with a better resolution.
These ways are kept in a specific table:
With this table, I can now extract the lattitude/longitude pairs for each node in the relevant ways and write them into a kml file.
The algorithm basically boils down to:
Here's a screen shot of the result:

node table is the fundamental table for open street map. Each node consists of a longitude (lon) / latitude (lat) pair
and thus defines a geographical point on the surface of the earth. The original schema has a few more attributes, such as changeset_id or version. I am not interested in these, so I don't load them:First, I need a table just to store each way. Again, I am not interested in attributes such as user or changeset, so I just load the way's id:
node_in_way relates nodes and ways:
Each member (that is either node, way or relation) is listed in member_in_relation.
Thus, exactly one of the attributes node_id, way_id or relation_id
is not null:
k) value (v) pair that
can be assigned to nodes, ways or relations. Often, the values for specific keys define what an object is. As in member_in_relation exactly on of
node_id, way_id or relation_id is not null.

Then, this pbf can be loaded into a sqlite db on the command line with
The script is on github: pbf2sqlite.py.
Open Street Map: convert pbf to xml
A Google Earth hiking map for the Säntis region with Open Street Map data
== operator in SQL that yields true if both operands are either null or have the same value?
Here's the truth table for the = operator:
| = | 42 | 13 | null |
| 42 | true | false | null |
| 13 | false | true | null |
| null | null | null | null |
col1 and col2 are null.
I suspect that in most cases this is not what the author of such a statement wants. Therefore, they will rewrite the query so:
Now, if there were a == operator with this truth table:
| == | 42 | 13 | null |
| 42 | true | false | false |
| 13 | false | true | false |
| null | false | false | true |
Maybe I am all wrong and there is such a thing somewhere. If you know of such an operater in any database product, please let me know!
A, A2Z and Z that I want to outer join from left to right:
 The first table,
The first table, A, contains the (primary keys) 1 through 7. I want my select to return each of these, that's why I use an outer join.
A's column i is outer joined to A2Z's column ia:
A.i = A2Z.ia (+).
(+) symbol indicates that a record should be returned even if there is no matching record. Note, the (+) is on the side of the = where "missing" records are expected.
Now, the records in A2Z should be joined to Z if A2Z's column flg is equal to y (colored green in the graphic above). For example, for the 1 in A, I expected the query to return the a in Z, for the 2 in A I expect no matching record in Z since the corresponding flg is either null or not equal to y.
This requirement can be implemented with a
A2Z.flg (+) = 'y'
Note, the (+) is on the side where missing records (or null values) are expected. Since y is neither missing nor null, it goes to the other side.
Finally, A2Z needs to be joined to Z:
A2Z.iz = Z.i (+)
When run, the select returns the following records:
A_I Z
---------- -
1 a
2
3
4
5
6
7
OpenStreetMap: convert an pbf to an sqlite database with Python
OSMNode, OSMWay and OSMRelation (see the
source at github).protoc.exe. After extracting this file, the environment variable PATH should be changed so that
it points to the directory with protoc.exe.
For the python installation, the full source protobuf-2.5.0.tar.bz2
is also needed. After extracting them, cd into the python directory and execute:
OpenStreetMap: convert an pbf to an sqlite database with Python

arcs that is an array.
arcs: array:

-1,-3 and goes to -3,-1 which is -2,2 relative to the first coordinate.
The third (and last) coordinate is relative 1,3 to the second coordinate. Hence, the entries in the arcs array
become:0, the second 1 etc.
If we want to refer to one of these arcs against its direction, the integer for the first arc is -1, for
the second arc, its -2 etc. This allows us to define the regions with the integers for the respective
confining arc.
For example, the first region looks like
id=foo is confined by the first arc (0) in direction of the arc, the
second arc (-2, note the negative sign) against the direction of the arc (negative sign!) and the fifth arc (again
against its direction, negative sign).
Finally, the country (or island) needs to be placed somewhere on the earth. The latitute-spread of the Northernmost and Southernmost
point of the country is 20 degrees, therefore, the scale is
d3.js, the folllowing code should do:
d3.select('.bar-chart').
selectAll('div').
data([194, 52, 228, 268, 163, 138, 92]).
enter().
append('div').
style ('width', function(d) {return d + "px"}).
text ( function(d) {return d });appended with its css width style set to the respective px width.
Since the divs are transparent per default, a bit of css is needed to make them visible:
.bar-chart div {
background-color:#fa5;
margin: 2px;
color: #713;
text-align: right}

python -m SimpleHTTPServer
This command creates a webserver that listens on port 8000, so that it can be accessed with a browser on localhost:8000
python -m SimpleHTTPServer 7777
Sihleggstrasse 23
8832 Wollerau
| Registered companies | Street | Location |
| 328 | Sihleggstrasse 23 | 8832 Wollerau |
| 304 | Murbacherstrasse 37 | 6003 Luzern |
| 222 | Technoparkstrasse 1 | 8005 Zürich |
| 203 | Gewerbestrasse 5 | 6330 Cham |
| 201 | Baarerstrasse 75 | 6300 Zug |
| 201 | Chamerstrasse 172 | 6300 Zug |
| 188 | Neuhofstrasse 5A | 6340 Baar |
| 185 | Industriestrasse 47 | 6300 Zug |
| 182 | Chemin du Château 26 A | 2805 Soyhières |
| 163 | Riva Albertolli 1 | 6900 Lugano |
| 162 | Haldenstrasse 5 | 6340 Baar |
| 157 | Churerstrasse 35 | 9470 Buchs |
| 157 | Dammstrasse 19 | 6300 Zug |
| 156 | Rue du Rhône 100 | 1204 Genève |
| 156 | Weissbadstrasse 14 | 9050 Appenzell |
| 149 | Poststrasse 6 | 6300 Zug |
| 148 | Baarerstrasse 78 | 6300 Zug |
| 145 | Industriestrasse 21 | 6055 Alpnach Dorf |
| 144 | Oberneuhofstrasse 5 | 6340 Baar |
| 140 | Baarerstrasse 2 | 6300 Zug |
create table dattyp (
without_dt,
dt_int integer,
dt_text text)without_dt) does not have an associated datatype with it,
the second and third columns do: integer and text, respectively.
insert into dattyp values ( 2, 2, 2)
insert into dattyp values ( 9, 9, 9)
insert into dattyp values (19, 19, 19)select without_dt from dattyp order by without_dt2
9
19select dt_int from dattyp order by dt_int2
9
19select dt_text from dattyp order by dt_text19
2
9integer columns are sorted numerically, while the text column is sorted alphanumerically.
insert into dattyp values ('28', '28', '28')select without_dt from dattyp order by without_dt2
9
19
28select dt_int from dattyp order by dt_int2
9
19
28select dt_text from dattyp order by dt_text19
2
28
9integer. Note that the strings can be inserted to the integer column as well:
insert into dattyp values ('foo', 'bar', 'baz')select without_dt from dattyp order by without_dt2
9
19
28
fooselect dt_int from dattyp order by dt_int2
9
19
28
barselect dt_text from dattyp order by dt_text19
2
28
9
bazsqlite3 module in Python:
import sqlite3
import os.path
if os.path.isfile('foo.db'):
os.remove('foo.db')
db = sqlite3.connect('foo.db')
cur = db.cursor()
cur.execute('create table bar (a number, b varchar)')
cur.execute("insert into bar values (2, 'two')")
cur.execute('insert into bar values (?, ?)', (42, 'forty-two'))
cur.executemany('insert into bar values (?, ?)', [
(4, 'four'),
(5, 'five'),
(7, 'seven'),
(9, 'nine')
])
for row in cur.execute('select * from bar order by a'):
print "%2d: %s" % (row[0], row[1])col 1,col 2,col 3
foo,bar,baz
one,two,three
42,,0 import csv
csv_file = open('data.csv', 'r')
csv_reader = csv.reader(csv_file)
header = csv_reader.next()
for record in csv_reader:
print 'Record:'
i = 0
for rec_value in record:
print ' ' + header[i] + ': ' + rec_value
i += 1 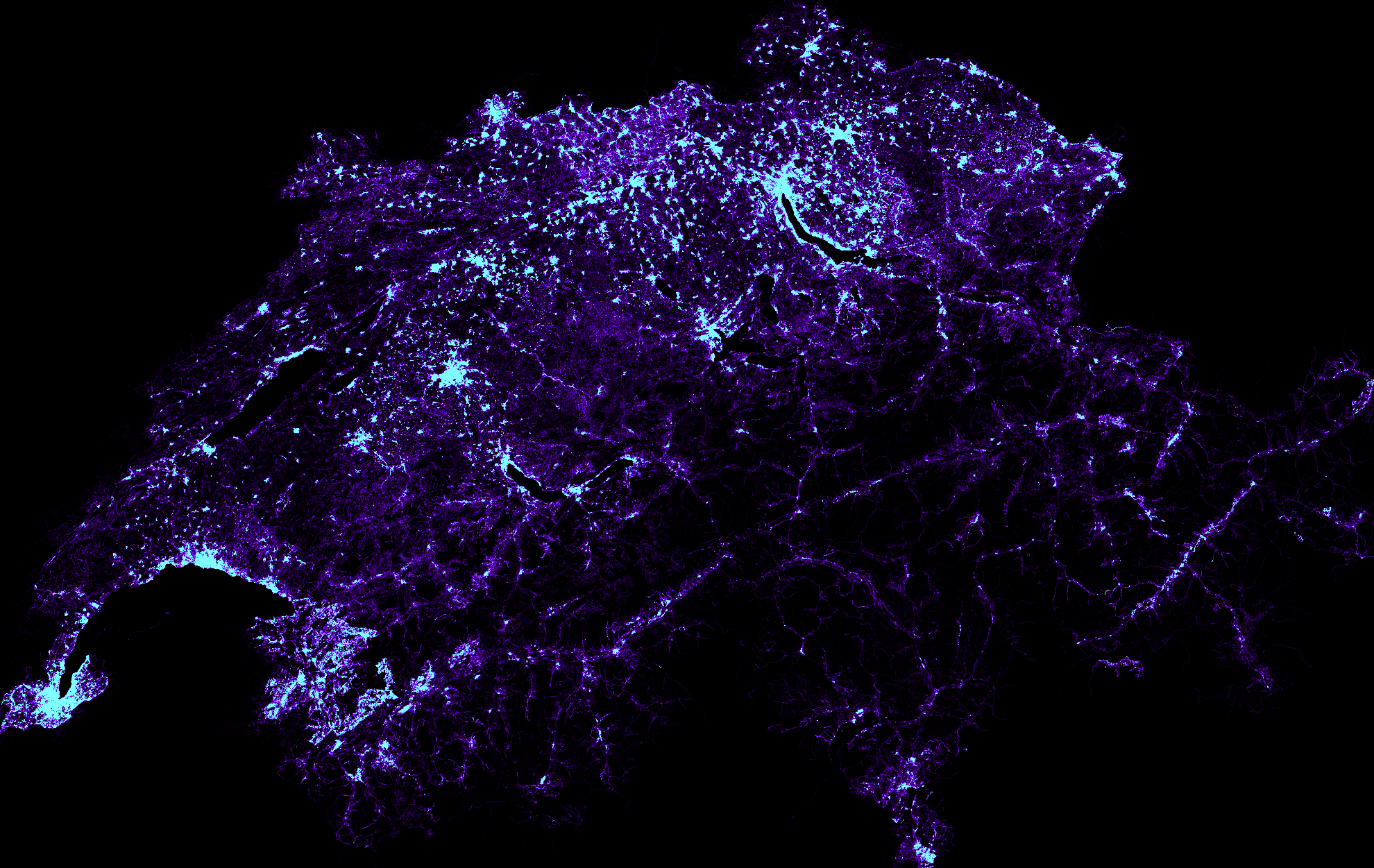{kind=link}
{kind=link}
{kind=link}